May 02, 2021 ( last updated : May 01, 2021 )
deeplearning
machinelearning
AI
In the field of Computer Vision, Image Segmentation is a crucial area that involves dividing images into segments to simplify or change the representation of an image into something more meaningful and easier to analyze. This blog dives into several prominent architectures that play a vital role in the development of image segmentation technologies.
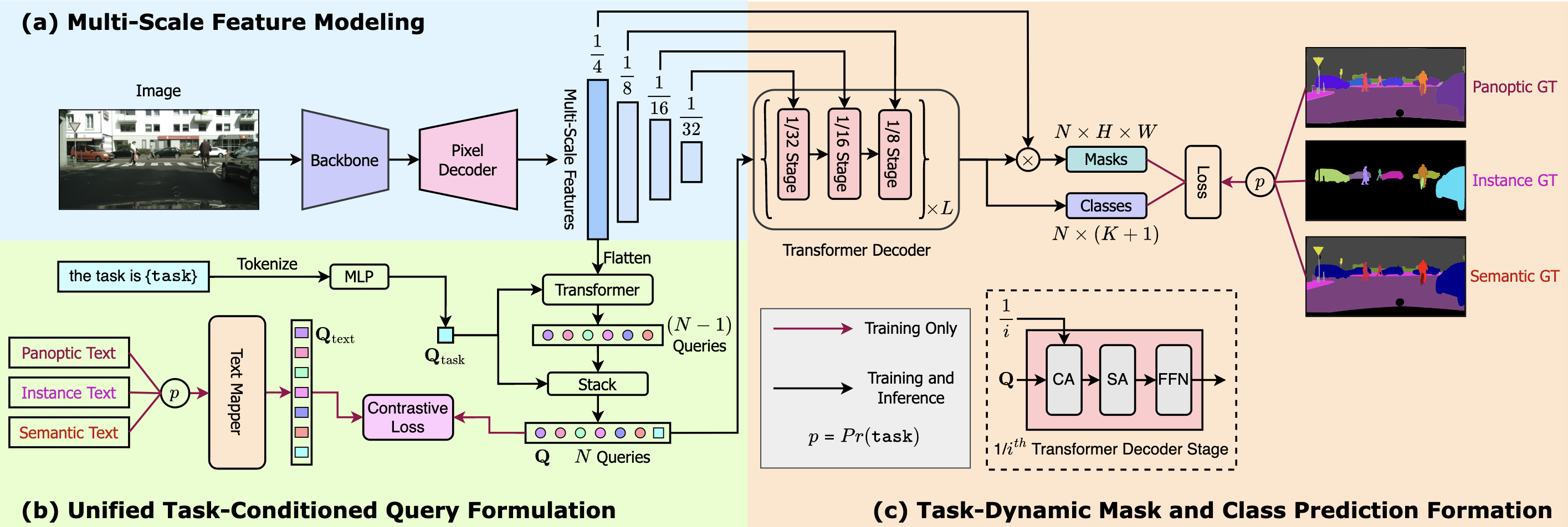
Originally designed for medical image segmentation, the U-Net architecture is notable for its effective use of data through the use of a symmetric encoder-decoder structure.
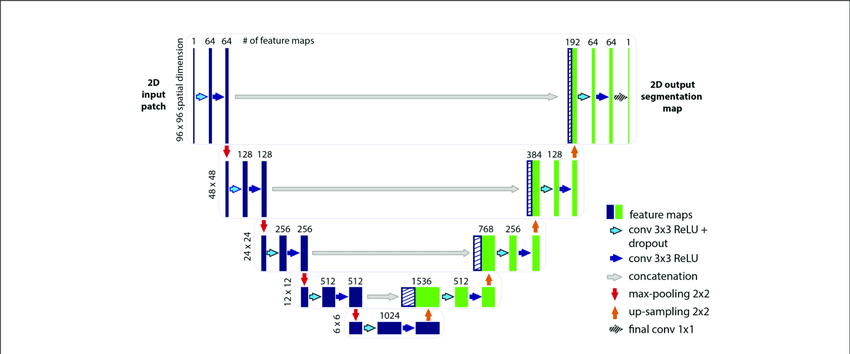
U-Net is designed with:
The performance of U-Net is often evaluated using the Intersection over Union (IoU) and Dice Coefficient metrics. Common loss functions include:
Transformers have recently been adapted for the task of image segmentation, leveraging their ability to handle global dependencies effectively.
Transformer models for segmentation like SETR or SegFormer integrate the transformer's self-attention mechanism to model long-range dependencies across the image.


These models often feature:
For transformer-based models, standard segmentation metrics such as IoU and the Dice coefficient are used. Loss functions typically include:
DeepLab is a series of models that excel at semantic segmentation using atrous convolutions to capture multi-scale information without losing resolution.
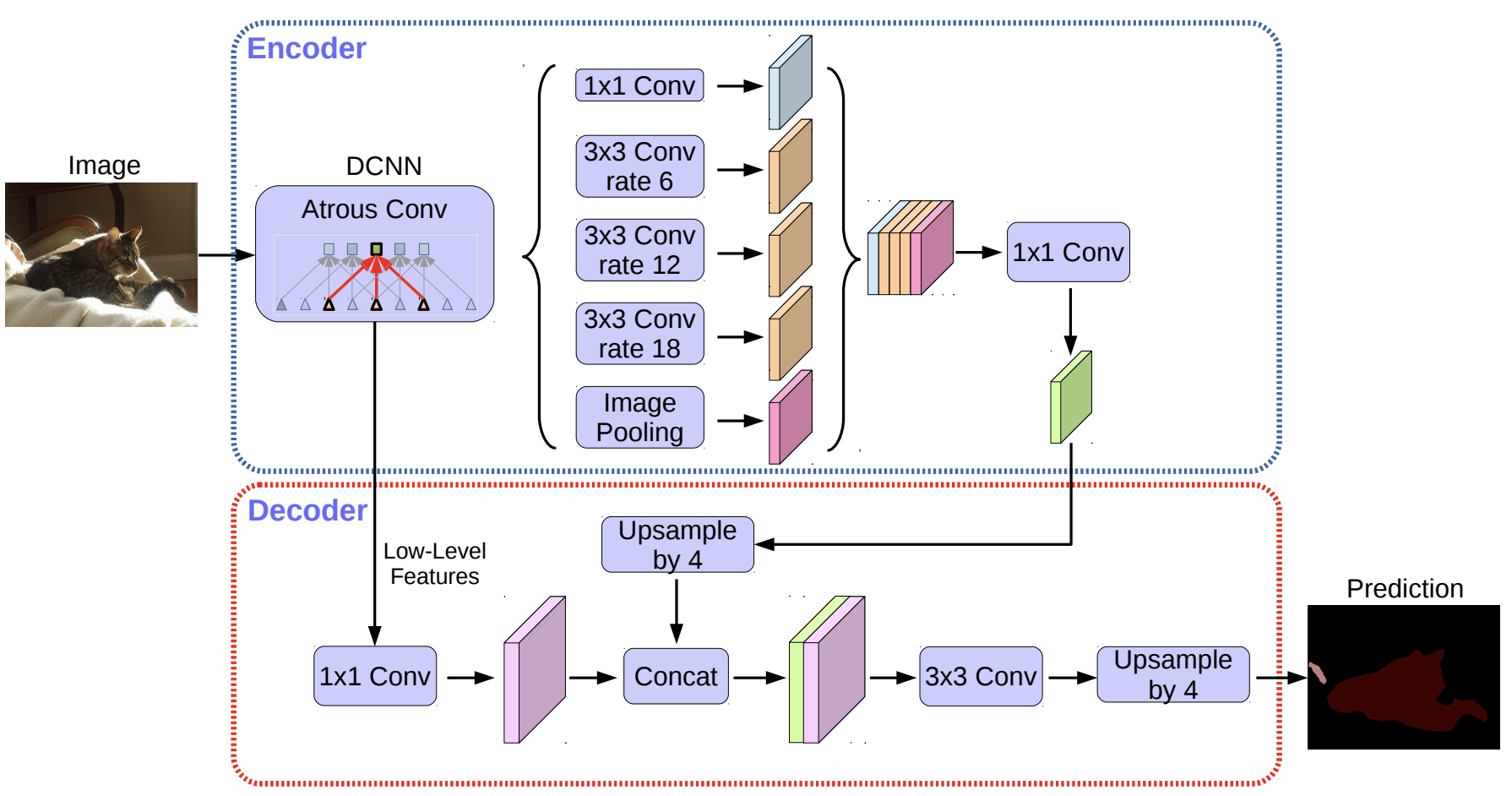
DeepLab architectures utilize:
DeepLab models leverage pixel accuracy and mean IoU for performance measurement. Losses include:
Each of these architectures offers unique advantages in handling the complexities of image segmentation, making them suitable for a variety of applications from medical imaging to autonomous driving.
Originally published May 02, 2021
Latest update May 01, 2021
Related posts :